05. System Architecture
System Architecture
The architecture employed by TwentyBN in order to effectively use the Jester dataset consists of a 3D CNN that extracts the spatio-temporal features, a recurrent layer (LSTM) to model longer temporal relations, and a softmax layer that outputs class probabilities.
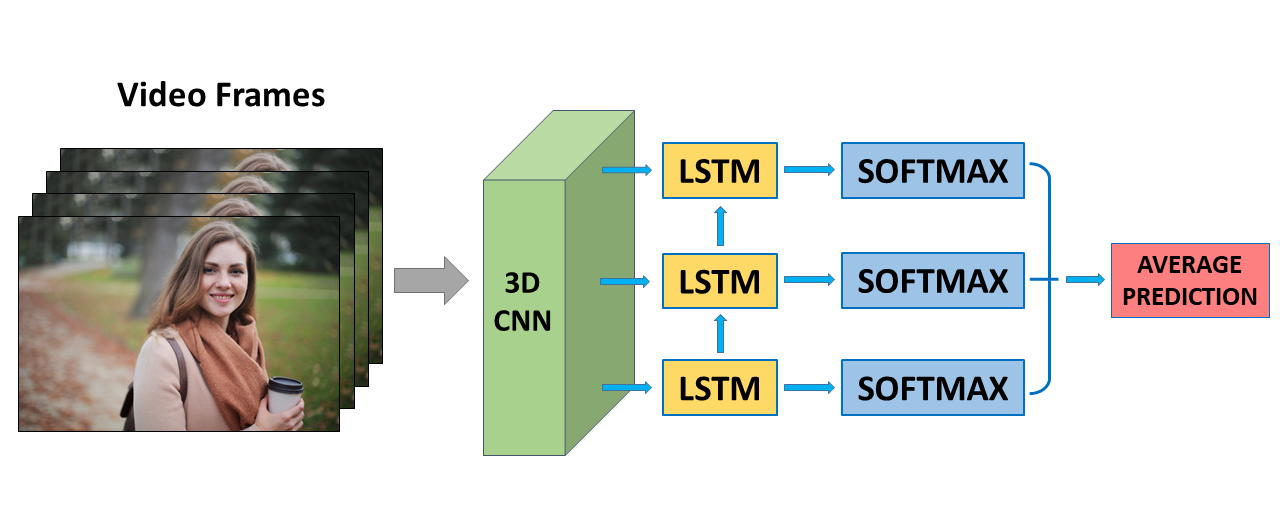
In this system the entire video is fed into the 3D CNN and the 3D CNN will output a series of features. In particular, if the video consists of N frames, the 3D CNN will output N feature vectors. Each feature vector can be viewed as a compressed representation of a small segment of the input video. The 3D CNN consists of a sequence of pairs of 3D convolutional layers having a stride of 1 for the temporal dimension and a stride of 3 for the spatial dimension. This choice of strides gives very good temporal and spatial features.
The series of features that are produced by the 3D CNN are then processed by an LSTM layer, allowing the system to model long time dependencies. Finally, the output of each LSTM layer is converted into a vector of class probabilities via a softmax layer. The outputs of the softmax layer are then averaged to obtain the best prediction.
During training, the obtained sequence of predictions from the softmax layer is averaged across time and used to compute the loss. This allows the system to predict the best class label before the full gesture is performed, allowing it to stay in sync with the video during testing.